(上調紅/下調藍)
(方向相反)
理想藥物能把 ALS 中過度上升的基因壓下、過度下降的拉回——紅(疾病異常)逐漸轉為藍(被校正)。
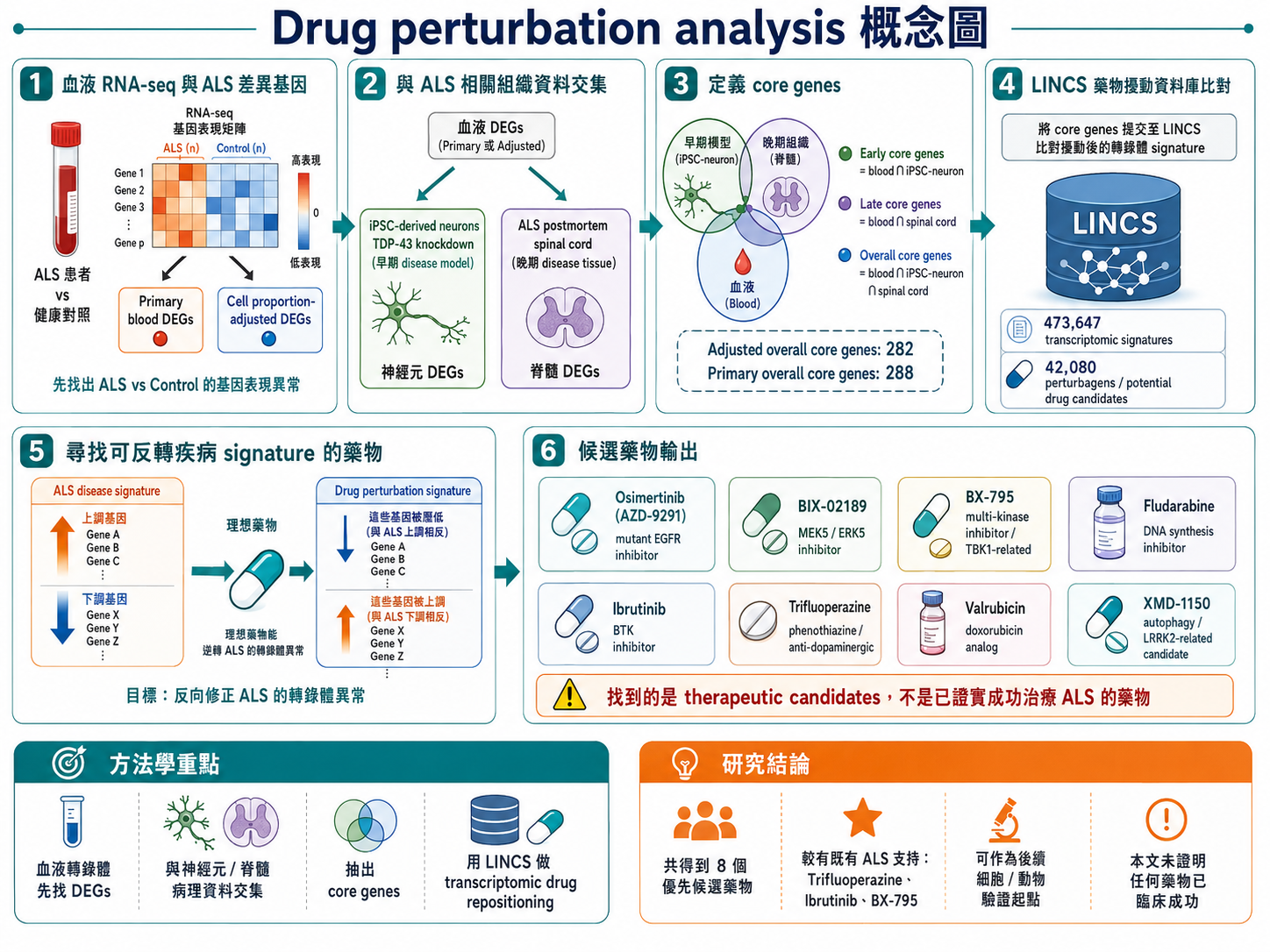
第二張圖的問題意識和第一張不同。第一張問的是:能不能分辨病人?而第二張問的是:既然 ALS 有特定的基因表現異常,那能不能找出某些藥物,去反向修正這種異常?
因此,drug perturbation analysis 的出發點,不是直接找已知 ALS 藥物,而是先建立一個疾病的轉錄體 signature。也就是說,研究者先問:在 ALS 血液中,到底有哪些基因上升了?哪些基因下降了?如果這組變化真的代表疾病的一部分,那麼理想的藥物應該要能做到相反的事情——把 ALS 中過度上升的基因壓下來,把 ALS 中過度下降的基因拉回來。這種概念有點像「分子層次的反向校正」。
研究的第一步,仍然是從血液 RNA-seq 出發。作者把 ALS cases 與 controls 比較,得到兩套血液差異基因:一套是原始的 primary DEGs,另一套是校正 immune cell proportions 後的 adjusted DEGs。之所以要做 adjusted 版本,是因為 whole blood 的基因表現很容易受到血球組成影響;有時候你看到的差異,不一定是單一細胞真的改變了功能,而可能只是因為某一類細胞變多了。因此作者希望把「細胞比例差異」與「真正與 ALS 病理相關的分子改變」盡量區分開來。
但研究者沒有直接拿這些 blood DEGs 去找藥。因為光是血液差異,不一定足夠代表 ALS 真正的核心病理。所以第二步,他們把血液 DEGs 分別拿去和兩個 ALS 相關資料集做交集:第一個是 iPSC-derived neurons with TDP-43 knockdown,代表較早期、偏機制性的神經元 disease model;第二個是 ALS postmortem spinal cord,代表較晚期、較接近終末病理的中樞神經組織。透過這種交集,研究者想找出那些不只在血液中異常、而且同時也在神經元模型或脊髓病灶中出現的基因。這些基因比較有機會是真正與 ALS 疾病過程有關,而不是單純的周邊變化。
於是,作者定義了幾種 core genes。若某基因同時存在於 blood 與 iPSC-neuron 中,可視為較偏「early core genes」;若存在於 blood 與 spinal cord 中,可視為「late core genes」;而如果同時出現在 blood、iPSC-neuron 與 spinal cord 三者中,就屬於 overall core genes。這一步的邏輯很重要,因為它其實是在做疾病訊號的「提純」:不是所有差異基因都等重,而是優先保留那些跨組織、跨模型仍然重複出現的訊號。文中最後得到的 adjusted overall core genes 為 282 個,primary overall core genes 為 288 個。
第三步,研究者把這些 core genes 丟進 LINCS 這類大型藥物擾動資料庫。LINCS 收集了大量「某種藥物處理細胞後,細胞基因表現會如何改變」的資料。也就是說,這個資料庫本身就是一個龐大的「藥物 → 轉錄體反應」對照表。當你把 ALS 的 core gene signature 拿去比對時,系統就可以問:有沒有某些藥物,它造成的基因表現變化方向,剛好和 ALS 的變化相反?如果有,這些藥就可能是值得進一步測試的候選者。
這個過程,本質上就是一種 transcriptomic drug repositioning(轉錄體層次的藥物重定位):不是直接證明藥有效,而是用大規模分子資料,先找出可能值得優先驗證的候選藥。
本頁為教育性整理,搭配主文圖解 drug perturbation analysis 的概念,非原文翻譯。原研究:Zhao, Y. et al. Gene expression signatures from whole blood predict amyotrophic lateral sclerosis case status and survival. Nature Communications 16, 9631 (2025). DOI